isorama
back to projectsBarrister Brief
A data engineering ETL pipeline project built with Python, GPT-API, & AWS.
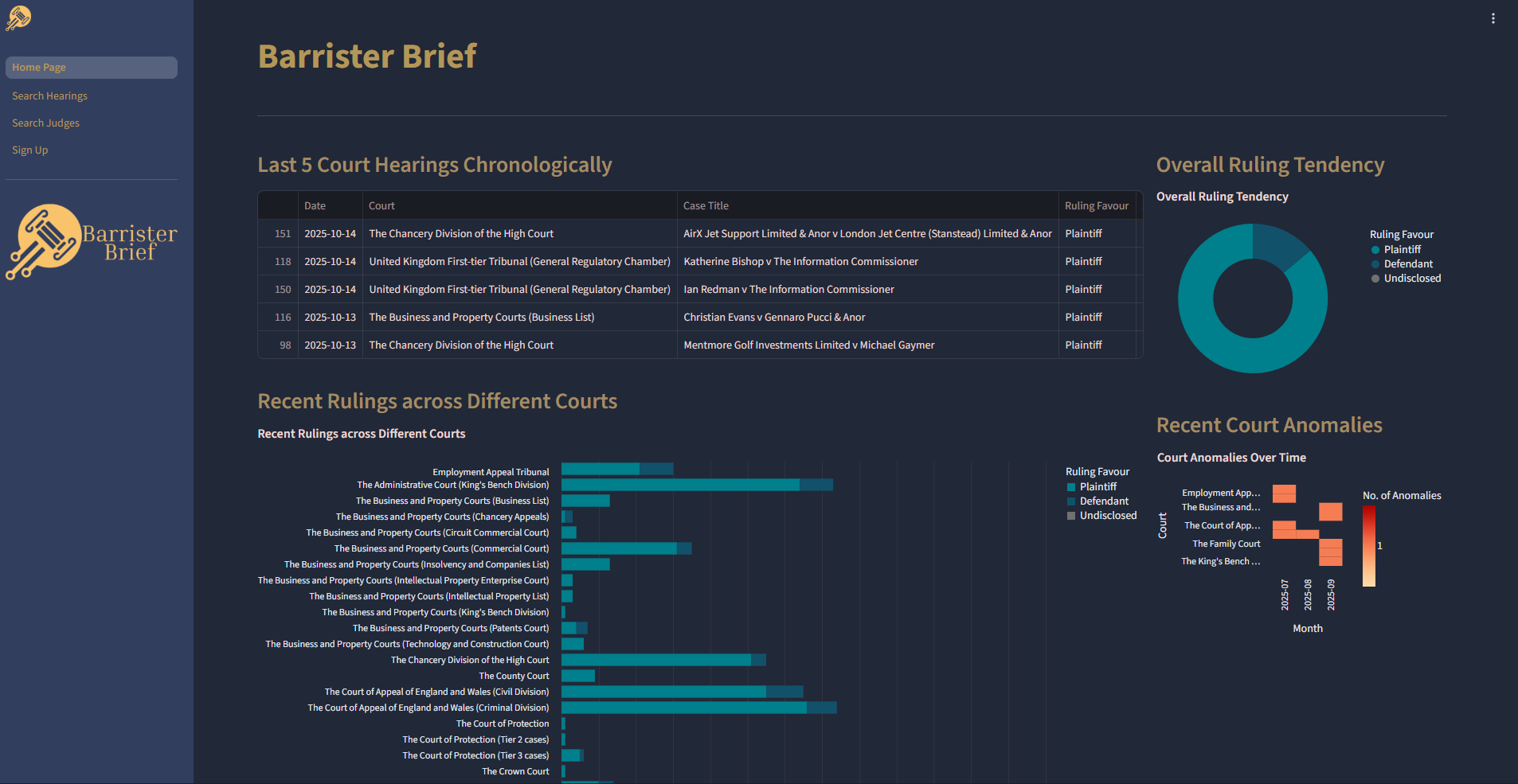
This project addresses the critical issue of public access to judicial information. The National Archives releases daily court transcripts in raw, plain-text format, making them effectively inaccessible for research into judge performance or potential bias. Our goal was to create a solution that transforms this unusable data into structured, searchable intelligence.
We engineered and deployed a cloud-hosted data pipeline to automate the entire process: ingesting the raw transcripts, structuring the data (identifying cases, rulings, and judges), and storing it in a robust database solution. This system enables sophisticated analytics, allowing users to easily answer questions like "How many cases has a judge sat?" or "How often do they rule a certain way?"
The final deliverable includes the deployed data pipeline, the comprehensive data backend, and an interactive dashboard website. By making complex court data transparent and discoverable, this project successfully enhances public oversight of the judicial system, supports data-driven journalism, and ensures greater accountability.